ソフトウェアのスクリーンショット:
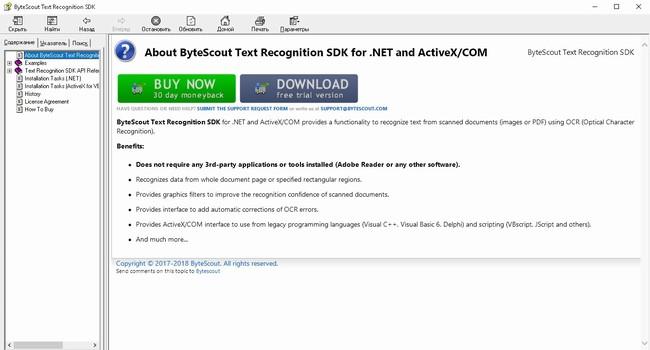
テキスト認識SDKを使用すると、元のドキュメントのレイアウトを保持している任意の写真、画像、スキャンされたイメージからテキストを抽出できます。主な特徴:さまざまなフォーマットのスキャン画像からテキスト認識と抽出を行い、入力レイアウトを完全に保存。認識されたテキスト量の正確な位置の定義。低品質文書の認識向上とOCRエラーの修正。画像フォーマットのサポートに続いて - JPG、PNG、TIFF。 PDFドキュメントのサポートでのテキスト認識。複数ページのサポート。矩形領域の指定
このリリースの新機能:
バージョン1.0.4.132:OCRイメージ前処理フィルタを削除するラインを大幅に改善しました。
改善されたPDFレンダリング
制限事項:
登録リマインダーのポップアップ、抽出されたデータの通知用ランダムウォーターマーク

コメントが見つかりません