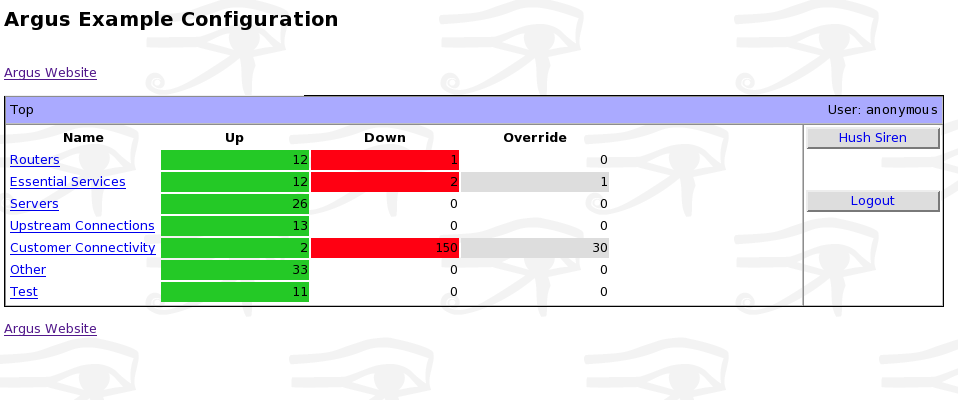
check_ganglia_metricを使用すると、任意のGangliaメトリックにアラートをトリガーすることができますNagiosのプラグインです。
check_ganglia_metricは重くウラジミールVuksanのcheck_ganglia_metric.phpに触発されていますが、多くの改良が付属していた。
<強い>
インストールの
check_ganglia_metricをインストールピップ#
...または:
#easy_installをcheck_ganglia_metric
の神経節の設定の
あなたのNagiosのサーバーおよび神経節メタデーモンが同じホスト上で実行されていない限り、あなたはおそらくあなたのNagiosのサーバーからのリモート接続を許可するようにgmetad.confを編集する必要があります。
nagios-server.example.comからの接続を許可するには:
trusted_hosts nagios-server.example.com
すべてのホスト(おそらくセキュリティリスク)からの接続を許可するには:
上のall_trusted
のコマンドラインでのテストの
まず、check_ganglia_metricはGangliaのメタデーモンと通信できるかどうかを見てみましょう:
check_ganglia_metric.py --gmetad_host = gmetad-server.example.com
&NBSP; - metric_host = host.example.com --metric_name = cpu_idle
OKステータス、CPUアイドル= 99.3%| cpu_idle = 99.3%;;;;
「ステータスOK」メッセージがcheck_ganglia_metric動作していることを示している。あなたがトラブルの仕事にこれを取得するがある場合は、詳細ログを再試行して何が間違って起こっているのより深い洞察を得るために(--verbose)を可能にした。
今度は警告しきい値を設定してみてみましょう:
check_ganglia_metric.py --gmetad_host = gmetad-server.example.com
&NBSP; - metric_host = host.example.com --metric_name = cpu_idle --critical = 99
重要なステータス、CPUのアイドル= 99.6%| cpu_idle = ;; 99 99.6%;;
私たちは、アイドル状態のCPUが「ステータス緊急」のメッセージは、それが働いたことを示し99.より大きかった場合は、「緊急」ステータスを返すことがcheck_ganglia_metric語った。そのcheck_ganglia_metricは公式のNagiosプラグイン開発ガイドラインに従って範囲としきい値を解析してください。
--helpオプション付きcheck_ganglia_metric実行簡単な説明、とコマンドラインオプションの完全なリストを参照してください。
のNagiosの設定のの
まず、コマンド定義を作成します。
{コマンドを定義
&NBSP;コマンド名check_ganglia_metric
&NBSP; COMMAND_LINE /usr/bin/check_ganglia_metric.py --gmetad_host = gmetad-server.example.com --metric_host = $ HOSTADDRESS $ --metric_name = $ ARG1 $ --warning = $ ARG2 $ --critical = $ ARG3 $
}
今、あなたはあなたのサービスの定義で上記のコマンドを使用することができます。
{サービスを定義する
&NBSP; service_descriptionのCPUのアイドル - 神経節
&NBSP; some_templateを使用
!&NBSP; check_commandのcheck_ganglia_metricはcpu_idle 0:20 0:0を!
&NBSP; host_nameのhost.example.com
}
何かが(キャッシュファイルが読み込めない例:/に書き込まれ、Gangliaのメタデーモンなど、到達できない)check_ganglia_metricと間違って行くまで、これは正常に動作します。その時点で、check_ganglia_metricに依存しているすべてのサービスは、おそらくアラートであなたを浸水、失敗します。当社は、サービスの依存関係を利用してこれを防ぐことができます。
私たちが必要とする最初の事はファイルの年齢をチェックするためのコマンド定義である:
{コマンドを定義
&NBSP;コマンド名のcheck_file_age
&NBSP; COMMAND_LINEは、/ usr / lib / nagiosに/プラグイン/ check_file_age -f $ ARG1 $ -w $ ARG2 $ -c $ ARG3 $
}
次に、我々はcheck_ganglia_metricのキャッシュファイルの年齢をチェックするサービスを定義します。真に有効であるために、このサービスはcheck_ganglia_metricに依存するすべての他のチェックより頻繁には少なくとも(好ましくは)としてチェックされる必要があることに注意してください。
{サービスを定義する
&NBSP; check_ganglia_metricためservice_descriptionキャッシュ
&NBSP; some_templateを使用
&NBSP;!!!check_commandのcheck_file_age /var/lib/nagios/.check_ganglia_metric.cache 60 120
&NBSP; host_nameのローカルホスト
&NBSP; CHECK_INTERVAL 1
&NBSP; max_check_attempts 1
}
そして最後に、私たちは実際のサービスの依存関係を設定する。私は私が私のディレクティブで正規表現を使用することができますNagiosのでuse_regexp_matchingを有効にしていることに注意してください。 「 - 神経節「固着することによりcheck_ganglia_metricに依存しているすべてのサービスの終了時に、私は自分自身多くの労力を節約することができます。
{servicedependencyを定義
&NBSP; host_nameのローカルホスト
&NBSP; check_ganglia_metricためservice_descriptionキャッシュ
&NBSP; dependent_host_name *。
&NBSP; dependent_service_description * - 神経節の$
&NBSP; execution_failure_criteriaのC、P
}
今、何かがcheck_ganglia_metricで問題が発生した場合には、一つだけアラートがキャッシュファイルについて送信されます、あなたが失敗するcheck_ganglia_metric原因となった問題を修正するまで、すべての依存サービスのチェックが一時停止されます。問題が解決されたら、(依存サービスのチェックを継続できるようになります)バックOK状態に「キャッシュcheck_ganglia_metricための "サービスを置くために、キャッシュファイルのタイムスタンプを更新する必要があります:
&NBSP;タッチ/var/lib/nagios/.check_ganglia_metric.cache
のヒントとコツの
それは、(-vv)ロギング」より冗長 "有効にすることで使用可能なホストとメトリックの完全なリストを取得することが可能です。 metric_hostとMETRIC_NAMEオプションが必要なので、あなたはここでは「鶏と卵」の問題を少し持っているが、それはOKです。ちょうどいくつかのダミーデータを供給。それはそのキャッシュをダンプする前に、プラグインは、「ホスト/メトリックが見つからない」エラーで終了時にエラーが、しません。
&NBSP; check_ganglia_metric.py --gmetad_host = gmetad-server.example.com
&NBSP; - metric_host =ダミー--metric_name =ダミー-vv
の の、このリリースの新機能:
- 追加 - -metrics_max_ageオプション
- README.rstにCHANGELOG.rstをマージします。
の要件の
- のPythonます。
- のNagiosます。
の制限事項の
- はPython 2.4では動作しません。
コメントが見つかりません