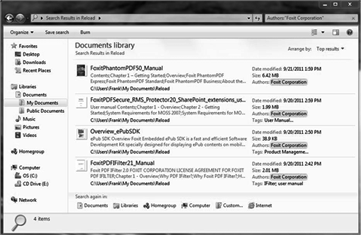
Foxit PDF IFilterは、MicrosoftのIFilterはインデクシングインタフェースの堅牢な実装です。これは、(たとえば、SharePointとSQL Server用)のIFilterインターフェイスをサポートするすべての検索および取得製品で動作します。このような製品は、(例えば、HTML)特定のファイル形式の形式固有のフィルタプログラム(と呼ばれるのIFilter)を使用します。 Foxit PDF IFilterはPDFドキュメントを目的としたようなプログラムである。文書を検索するためのユーザインタフェースは、エクスプローラ、ウェブブラウザ、データベースフロントエンド、クエリスクリプト、またはカスタムアプリケーションであってもよい。 Foxit PDF IFilterは、プラグインのフルテキスト検索エンジン用として機能します。検索エンジンは、通常、以下の二つのステップで動作します:*検索エンジンはインデックスをすべての文書または(PDFドキュメントを含む)を新たに変更された文書、指定された場所(ファイルフォルダまたはデータベース)を通過した後、内部データベースにインデックス作成結果を格納する。 *ユーザーは、彼らが検索したいキーワードを指定して、検索エンジンは、内部データベースにインデックス作成の結果を検索し、その後、指定されたキーワードが含まれているすべてのドキュメントをユーザーに応答する。ステップ1の際、検索エンジン自身はPDFドキュメントのフォーマットを理解していない。そのため、適切なPDF IFilterは、Windowsのレジストリで検索し、FoxitのPDF IFilterを見つけます。 PDF IFilterはPDF形式を理解しているので、それは、組み込みの書式を除外した文書からテキストを抽出し、再び検索エンジンにテキストを返します。以下の検索エンジンの環境でのFoxit PDF IFilterは機能:*は、Microsoft SharePoint Server:SharePoint Server 2007の、SharePoint Server 2010の、SharePointサーバー2013 * Microsoft Exchange Serverの:Exchange Server 2007では、Exchange Server 2010の*は、Microsoft SQL Server:SQL Server 2008の、SQL Serverの2010、SQL Serverの2014
のこのリリースのの新機能は次のとおりです。
ハイパフォーマンスインデキシングます。
の制限事項の
30日間の試用ます。
コメントが見つかりません