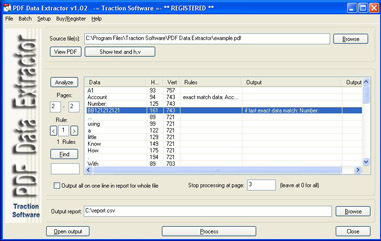
PDF Data Extractorは、PDF内の特定のテキスト情報を抽出することができます。たとえば、アカウント番号、名前、住所などのデータを抽出し、この情報をExcel CSVファイルに出力する必要があるPDF文がある場合は理想的な製品です。それは水平、垂直のテキスト位置マッチングを使用し、より高度なマッチングのために、条件マッチングのためのルールシステムを有する。口座番号:テキストが同じページにある場合のみ一致します。異なるフィールドも1つにマージすることができますので、First NameとSurnameをCSVファイルの1つのフィールドとして出力し、スプレッドシート形式のpdfをcsvファイルに変換して、多くのオプションを利用できます。データ抽出、コマンドラインでの実行、ヘッダー出力、ページ番号フィールド、ファイル名フィールド、処理するファイルのバッチリスト。
また、抽出されたデータに基づいてファイルを新しい場所にリネームまたはコピーすることもできます。
注:このソフトウェアはスタンドアロンです。つまり、Adobe Acrobatを実行する必要はありません。
評価の制限事項は次のとおりです。 - バグモードでは、nag画面、試用テキスト、5ファイル
特定のPDFファイルを作成するカスタムデータ抽出プログラムが必要ですか?
私たちは、この製品の様々な特注バージョンを行ってきました。警察の報告書、請求書などのより複雑なレポートのために、csvファイルの出力に、より簡単なファイルを/ file outインターフェイスで提供しています - 妥当な見積りのために私達に連絡してください。このリリース:
バージョン1.05:
1.追加ソートオプション。
バージョン1.04の新機能:
バージョン1.04:
1.追加された行は浮動行サイズに対して調整され、hテキストに一致します。
すべてのフォント、埋め込みフォントおよびサブセットフォントを含むように変更されたテキストダンプ
制限:
Nags、5ファイル試用版、試用版テキスト
コメントが見つかりません