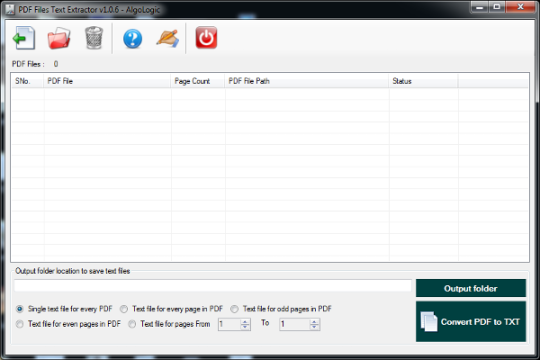
PDFファイルのテキスト抽出v1.0.6デベロッパーは、PDFファイルからプレーンテキストを抽出するためのソフトウェアであり、多くのオプションを使用してファイルを.txtに保存されます。保存した.txtファイルは任意のテキストエディタで開くことができます。 TxtのコンバーターへのPDFは、特定のページ、ページ範囲、シングルクリックで多くのPDFファイルから代替ページからプレーンテキストを抽出するために、さまざまなオプションをサポートしています。 PDFファイルのテキスト抽出v1.0.6デベロッパーソフトウェアはPDFファイルを処理するためには、Adobe Acrobatソフトウェアのような他のソフトウェアを必要なすべてのPDFファイル(任意のバージョン)とされないために動作します。
要件のための無料トライアルをダウンロードすることができますtxtがコンバータへのPDFます。 の.NET Framework 2.0 この制限事項: この限定機能
PDFファイルのテキスト抽出v1.0.6デベロッパーソフトウェアは、バッチ処理で非常に高速なツールとプロセスの多くのpdfファイルです。 PDFファイルは1つずつ追加することができますまたはフォルダ/ディレクトリからすべてのPDFファイルを閲覧することができます。それはあなたの貴重な時間を節約しながら、それは高価なソフトウェアではありません。 PDFファイルのテキスト抽出v1.0.6デベロッパーの試用版は、Windowsプラットフォーム用の無料ダウンロードすることができます。
主な特長
PDFファイルのテキスト抽出は、バッチ処理で.TXTファイルにPDFファイルの数千に変換することができます。
また、PDFファイルからのUnicode /プレーンテキストを抽出し、テキストエディタで開くことができ.txtファイルに保存されていることができます。
テキストコンバータへのPDFは、各PDFファイルのsaparateテキストファイルを作成します。
これは、PDFファイルから、またはPDFファイルの特定のページ範囲から奇数と偶数ページからテキストを抽出することができます。
PDFのすべてのバージョンをサポートしています。
Windowsプラットフォーム

コメントが見つかりません