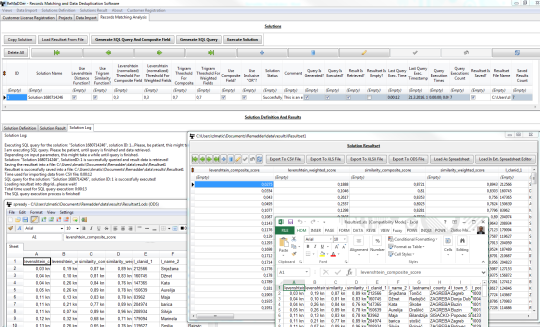
Remadderは、2つの別々のデータセットに関連するレコードを識別するために、またはデータセットの重複レコードを識別するための両方に使用することができるソフトウェアツールです。タスクのこのクラスは、一般的に、レコードリンケージ、データマッチングとしてrefferedされ、データが検出、データ重複排除機能を複製します。
Remadder特に成功した二つの関連データセットは正確な共通の一意の識別子を共有しないファジーデータマッチングの難しい問題に対処します。その代わり、通常、簡単な主キー/外部キーのリレーションのやり方で、そのような場合にはデータ照合は、文字列あいまい一致の類似性に基づいて確立されなければなりません。これは、しかし、今日でも最も強力なコンピュータ用排気複雑かつ資源豊富な作業です。
正規化されたレーベンシュタイン距離とトライグラムの類似性:Remadderは、二つの異なる文字列比較の類似性指標の組み合わせを利用することにより、あいまい一致解析のための発明と実用的なアプローチを使用しています。これらは、最良の結果を提供するために、柔軟な方法で組み合わせることができます。
ユーザーが完全一致制約、ファジーマッチング制約とビジュアルで直感的な方法で他のすべての制約を定義できるようにすることで、あいまい一致解析のすべての複雑さはユーザから隠されていると、彼/彼女は技術的な問題ではなく、ビジネス・ケースに焦点を当てることができます。 Remadderソフトウェアは本当に輝いて、はっきり競争から一線を画しところです。
その直感的なグラフィカル・ユーザ・インタフェースと低価格により、Remadderは、どのようなビジネスケースのあいまい一致レコードの連携のための優れたソリューションを提供します。
この15日間の試用
コメントが見つかりません