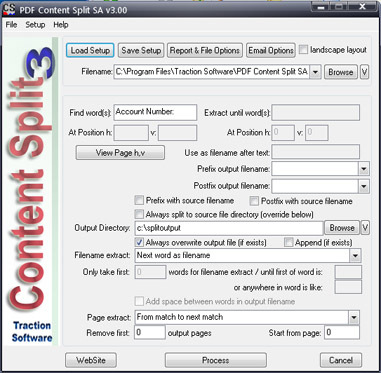
PDFコンテンツスプリットSA(スタンドアロン版)はPDF内のテキスト情報に分割できます。たとえば、アカウント番号の分割が必要なPDF文がある場合は理想的な製品です。 pdf内の単語を検索し、開始範囲と終了範囲をマーキングしてから自動的にドキュメントを分割することで、簡単に行えます。
多くのオプションが利用可能です:コンテンツ分割、コマンドラインでの実行、出力ファイル名としてのpdf内の単語の取り込み、テキストまでの抽出、一意のテキストの抽出、以前に一致した場合の追加オプション
このリリースで新しく追加されたもの:
バージョン3.16
1. 4kモニタおよびその他のdpi設定のスクリーンdpi修正。
バージョン3.14の新機能:
バージョン3.14
1.負の値を持つ外来文字の修正
2.メモリ不足の原因となっているサイズの大きいワードについて修正する。
3.電子メールフィルタリングを追加しました。例えば%[]
4.電子メールでエラーが発生した場合は、処理を続行し、ログに報告します。
5.テキスト抽出のための件名にh、v範囲のサポートが追加されました。私の主題請求書:[200-300,500]をあなたが期待したとおりに。
6.セットアップメニューで起動する前に、出力フォルダからファイルを削除しました - >その他の設定
7.特定のpdfの修正、13.11へのpdfエンジンの更新
8. dosコマンドラインから実行すると、戻りコードとして分割されたファイルの数が返されるようになりました。
電子メールのための更新されたヘルプ。
バージョン3.10の新機能:
バージョン3.10
1.電子メールにソフトハイフンサポートが追加されました。
2.ファイル名のサポートの間に単語を追加しました。
バージョン3.07の新機能:
バージョン3.08の新機能:
バージョン3.08:PDFビュー/ヌルのクラッシュ修正を抽出します。 >
バージョン3.07
1. pdftextdump.dllのクラッシュの問題を修正してください。
制限:
20ページ試用版、nag画面
コメントが見つかりません