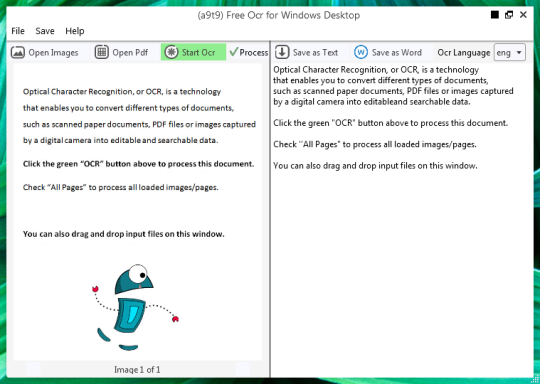
このフリーOCRソフトウェアがイメージファイルおよびPDF項目からテキストを抽出する。たTesseract OCRエンジンのグラフィカルユーザインタフェース(GUI)。
この
アプリケーションのインストールは簡単で、より重要なのは、自由に使用する、オープンソースの100%アドウェアやスパイウェア無料です。
あなたは、画像やPDFファイルを開くことができます。ソースファイルの内容は、左側のウィンドウに表示されます。あなたは複数ページのドキュメントを開いた場合は、複数のページとしてあなたの文書は、または、それらを切り替えるために下部にある矢印を使用している場合は、
あなたは緑のOCR]ボタンをクリックすることで、OCRを起動し、あなたは第2の右のウィンドウに結果が表示されます。出力テキストは、テキストファイルまたはWord文書として保存することができます。
この
残念ながら、変換の質はそれほど大きくない。シーンの背後には、たTesseractオープンソースのOCRエンジンを使用しています。品質は言語から言語まで変化する - ので、先に行くと、それはあなたのニーズのために十分であるかどうかをテスト
。
ソフトウェア開発者やオタク:Windowsデスクトップツールの無料OCR本質たTesseract OCRエンジンのためのグラフィカル·ユーザー·インターフェース·フロントエンド(GUI)です。完全なソースコード(GPLライセンス)が利用可能である。
英語、フランス語、イタリア語、ドイツ語、スペイン語、ポルトガル語(ブラジル)、オランダ語:ソフトウェアのOCRエンジンは、次のOCR言語をサポートしています。バージョン3以降では、クロアチア語、チェコ語、デンマーク語、オランダ語、英語、ドイツ語(標準およびフラクトゥールスクリプト)、ギリシャ語、フィンランド語、フランス語、ヘブライ語、ヒンディー語、ハンガリー語、アラビア語、ブルガリア語、カタロニア語、中国語(簡体字および繁体字)を認識することができますインドネシア語、イタリア語、日本語、韓国語、ラトビア語、リトアニア語、ノルウェー語、ポーランド語、ポルトガル語、ルーマニア語、ロシア語、セルビア語、スロバキア語(標準およびフラクトゥールスクリプト)、スロベニア語、スペイン語、スウェーデン語、タガログ語、タミル語、タイ語、トルコ語、ウクライナ語、ベトナム語。
コメントが見つかりません