ソフトウェアのスクリーンショット:
非構造化データを扱う
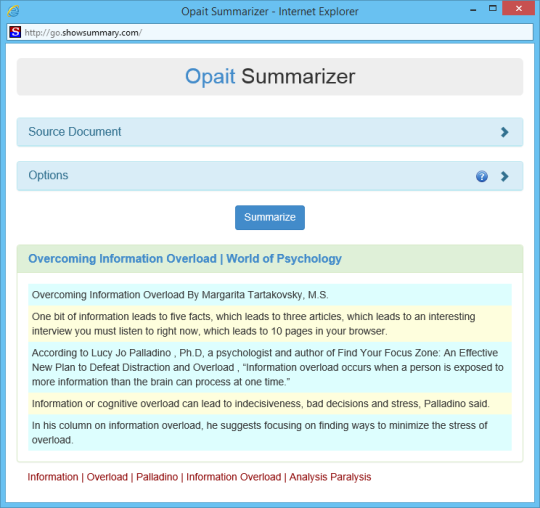
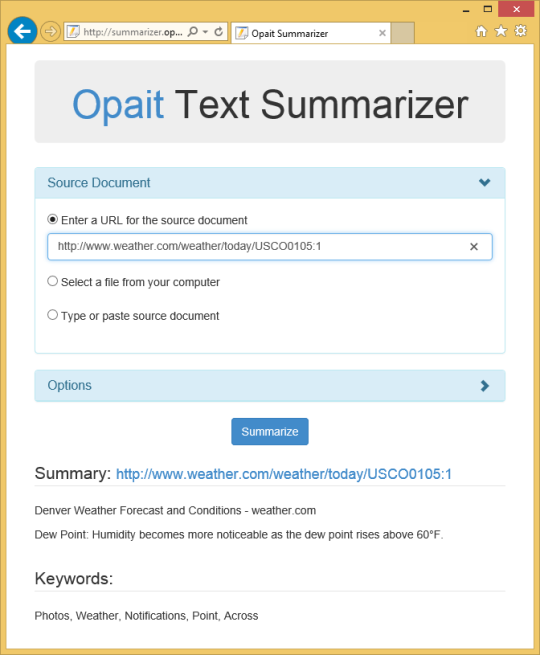
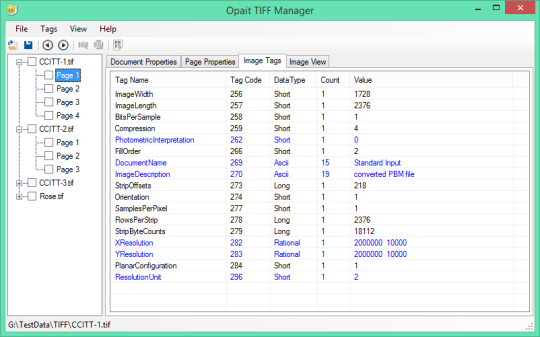
多くのアプリケーションでは、フォーマットされた、またはマークアップされた文書のテキストコンテンツにアクセスする必要があります。文書をアーカイブする組織は、多くの場合、文書を検索可能にすると、ドキュメントアーカイブのコンテンツアグリゲーション、報告およびマイニングを可能にするためにテキストコンテンツにアクセスする必要があります。検索と検索アプリケーションはまた、さまざまなファイル形式からテキストを抽出し、トークン化する必要があります。
の要件の:。 は、.NET Framework 4.5
アクセスした文書からテキストを抽出するための一つの標準的なメカニズムは、Microsoftの検索エンジンで使用されるIFilterのプラグインインタフェースによって提供される。さまざまなファイル形式をカバーし、Microsoftやその他のベンダーによって開発されたいくつかのIFilter実装があります。標準または信頼性とテキスト抽出の品質は、複数のIFilterの開発者間で変化します。
Opaitテキストフィルタ既にホストコンピュータにインストールされているのIFilterにシンプルなインターフェイスとファイル形式を直接操作し、デフォルトのIFilterの実装を改善少数のカスタムテキスト抽出フィルタの小さなユーティリティプログラムです。
テキストを抽出するためのインタフェースが含まれており、.NETアプリケーションにテキストフィルタを統合するために使用することができOpait.Filtersと呼ばれる小さなクラスライブラリによって提供されます。
コメントが見つかりません